半精度 - 深度学习中的类型(一)
半精度(fp16)在深度学习中是非常常用的一种数据类型,他可以加速训练或推断、节省显存的使用。较新型号的英伟达显卡设备几乎都支持半精度数据类型的加速,典型的是图灵架构的 V100 显卡,其半精度的训练速度远远超过了单精度(fp32)的训练速度。而得益于混精度和Scaler等技术的运用,半精度所训练的模型在指标上几乎持平单精度的结果。
在 PyTorch 中如何使用半精度训练
PyTorch 中使用半精度的训练非常简单,只需在原有的基础上增加少量代码即可:
scaler = torch.cuda.amp.GradScaler()
with torch.autocast():
optimizer.zero_grad()
logits = model(inputs)
loss = some_loss_fn(logits, targets)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
使用上面的代码就可以开启混精度的训练模式,能加快训练速度并减少显存占用。如果还想知道更多细节,我们需要深挖一下,例如这里的 GradScaler 和 torch.autocast 分别是做什么的。
autocast
torch.autocast 可以作为上下文管理器或装饰器来使用,即使用 with 语句或 @ 符号来修饰代码:
from torch import autocast
with autocast():
...
# 或者
@autocast()
def forwad_func():
...
在受 autocast 影响(上面代码中的 ... 部分)的 Tensor 操作会尽可能的自动转换为 fp16 的数据类型进行计算,在这部分代码中,所有 Tensor 的数据类型是不定的,因为并不是所有的操作都可以使用 fp16 类型,但无需担心,autocast 会选出最合适的方案,用户不要在 autocast 中自行操作 Tensor 的类型,在 autocast 中手动修改类型,或是逻辑上依赖类型都是不安全的做法。在 autocast 中应该完全忘掉类型,交给 PyTorch 自行处理。
第二个要注意的点是 inplace 操作无法被自动切换类型,PyTorch 中很多操作都提供了 inplace 版本,例如 addmm 的 inplace 版本是 addmm_。inplace 的意思是直接修改输入的值而不提供返回值,其好处是可以节省小部分内存,因为没有产生中间变量,但坏处是会无法使用很多高级特性,autocast 就是其中之一。在实践中我基本会尽量避免使用 inplace 操作。
可以在 PyTorch 的文档中找到所有支持自动切换操作的列表:
Scaler
其实跟半精度/混精度相关的东西,基本都在 autocast 里了,现在来说说经常跟 autocast 成对出现的 Scaler 吧。
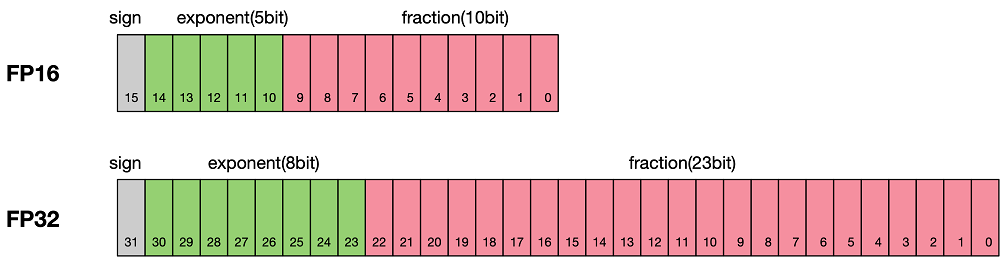
在训练的场景中,单纯地使用半精度会带来一个问题:如果某个操作在模型的前向(forward)过程中使用了 fp16 的数据类型,那这个操作所产生的梯度也是 fp16 类型的,大多数时候梯度都是非常小的数值。而 fp16 类型能表达的尾数部分的范围相比于 fp32 来说非常有限:
所以对于绝对值非常小的梯度来说,可能会超出 fp16 所能表达的范围,这被称作数值下溢,那解决办法就是把数值扩大(即乘以某个比较大的数值 factor)然后再计算梯度,这样来避免 fp16 无法表达极小值的情况。
回到代码中,我们来看看 scaler 相关的几行代码具体做了什么事情:
# 创建一个 Scaler
scaler = torch.cuda.amp.GradScaler()
with torch.autocast():
optimizer.zero_grad()
logits = model(inputs)
loss = some_loss_fn(logits, targets)
# 放大 loss,等同于 (loss * factor).backward() factor 是一个较
# 大的值,默认为 65536,可以在 scaler 初始化的时候手动进行设置
scaler.scale(loss).backward()
# 对所有梯度转换成 fp32,再进行 unscale,也就是 grad / factor,因
# 为已经是 fp32 类型了,所以不会发生下溢,然后再调用 optimizer.step
scaler.step(optimizer)
# 根据一些策略动态调整 Scaler 使用的 factor,如果 factor 过大或过小
# 则在上一步 step 中均有可能产出数值溢出,那么可以根据上一步中是否出现
# 溢出的情况来自动调整 factor 的大小,因此这一步需要始终在 step 之后
# 调用
scaler.update()总结一下
- autocast 可以在几乎所有场景下使用,训练、验证、甚至是部署到生产,我甚至认为 PyTorch 应该将 autocast 作为缺省的逻辑。
- GradScaler 仅在训练中使用,目的是防止数值下溢。