
一键部署 InternLM(书生·浦语)
最近商汤发布了大模型 InternLM(书生·浦语),根据 OpenCompass 的榜单显示,其综合性能不错,特别针对中文环境,本文简单介绍一下如何快速部署 InternLM 模型。
部署
部署的方式很多,这里我使用了官方最推荐的方式 —— lmdeploy。在 Featurize 平台最新的 PyTorch 镜像中,打开终端运行下面的代码就能部署 internlm-chat-7b 模型。如果是在其他地方部署,则至少需要安装好 Python3 等常用软件。
curl -s https://chenglu.me/assets/deploy_internlm.sh | bash -s internlm/internlm-chat-7b
可以通过替换参数来部署其他模型,目前支持的参数有:
internlm/internlm-chat-7binternlm/internlm-chat-7b-8kinternlm/internlm-chat-20blmdeploy/turbomind-internlm-chat-20b-w4
同时我也将部署代码放在了 GitHub Gist 上。
因为需要下载的文件很大,受带宽和网络质量影响,整个部署过程会比较长,Featurize 平台做了网络加速,模型的下载和部署都都会在 5 分钟左右完成,小的模型(7b)时间更短。
在 Featurize 上部署完成后,需要使用 featurize port export 6006 来将端口暴露到公网,然后根据提示来访问界面。
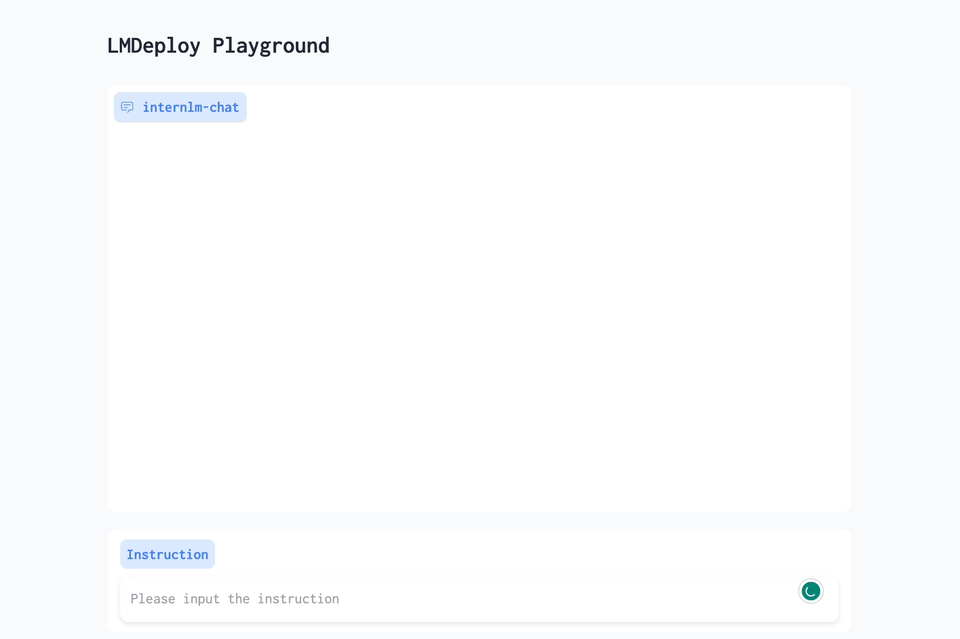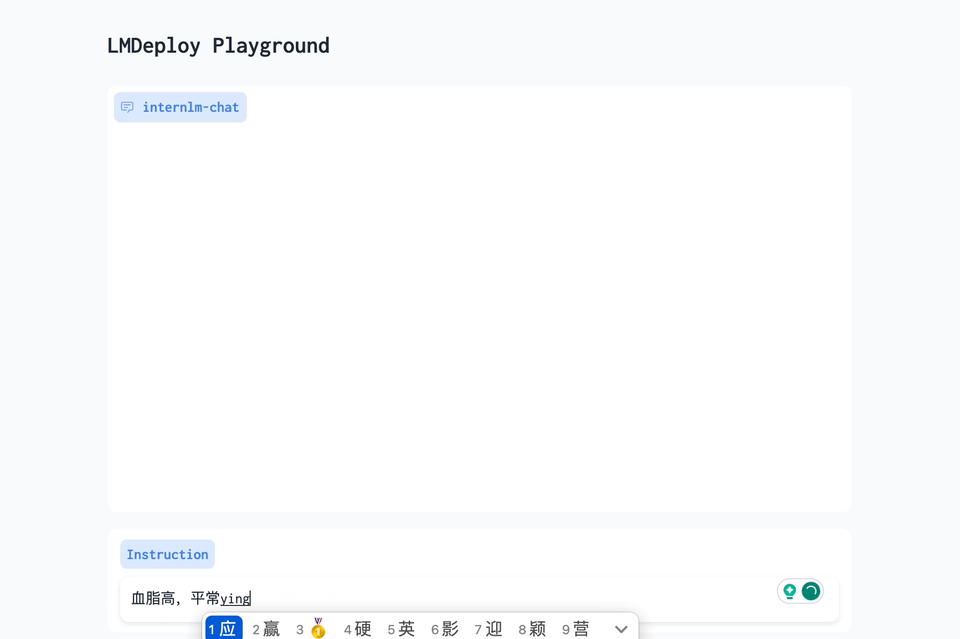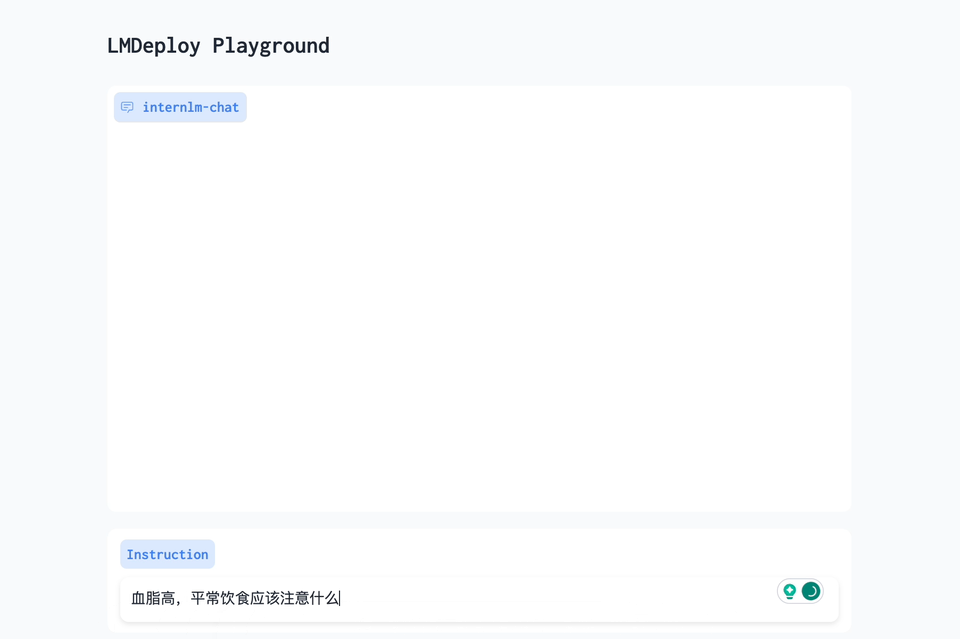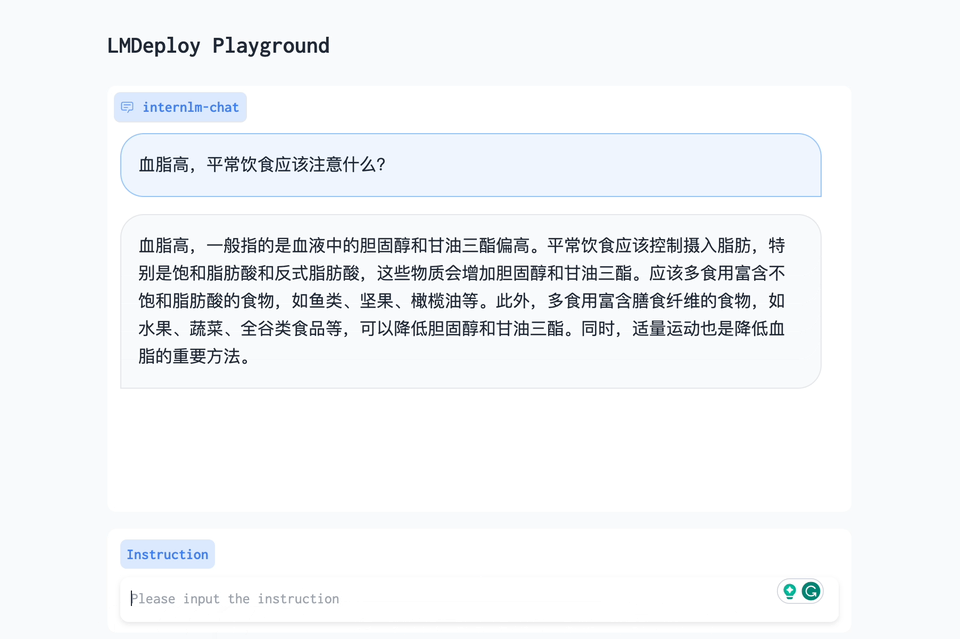
从下图中可以看到,单张 4090 的推理速度也是非常的快的。
显存要求
大部分模型仅需要单张 3090 / 4090 就可以完成部署。以下是笔者在 Featurize 平台完成的测试。
| 模型 | 显卡 x 数量 |
|---|---|
| internlm-chat-7b | 4090 x 1 |
| internlm-chat-7b-8k | 4090 x 1 |
| internlm-chat-20b | 4090 x 4 |
| turbomind-internlm-chat-20b-w4 | 4090 x 1 |