
高效使用 Google Colab
Colab 已经被越来越多的人用于炼丹,但我也听到很多抱怨的声音,例如 Colab 太慢,不方便,还会中途强迫掉线 etc… 这篇文章就跟大家介绍一下正确使用 Colab 的姿势。
氪金
白嫖党先别跑。
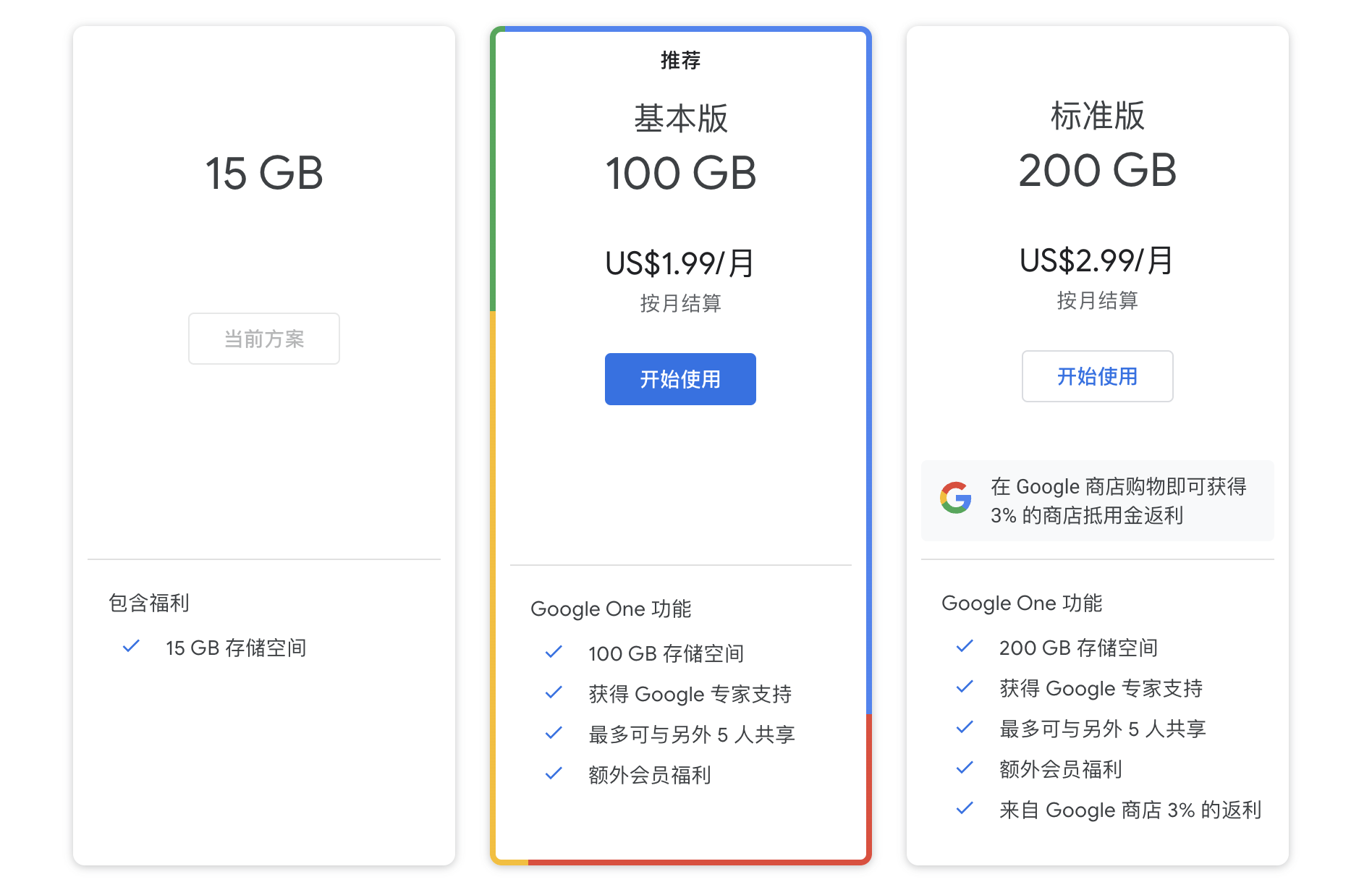
白嫖的所提供的显卡性能实在堪忧,建议开 Colab Pro。
| 对比项 | 白嫖 | Colab Pro | Colab Pro + |
|---|---|---|---|
| 内存 | 最高 12G | 最高 80G | 最高 80G |
| 显卡 | K80 / T40 | P100 / V100 / A100 | P100 / V100 / A100 |
| CPU | 2核 | 最高 12 核 | 最高 12 核 |
| 后台运行 | No | No | Yes |
| 价格 | free | 9.9$ | 49.9$ |
来点真相,我开的是 $9.9 一个月的 Colab Pro,下面是我获得的实例截图
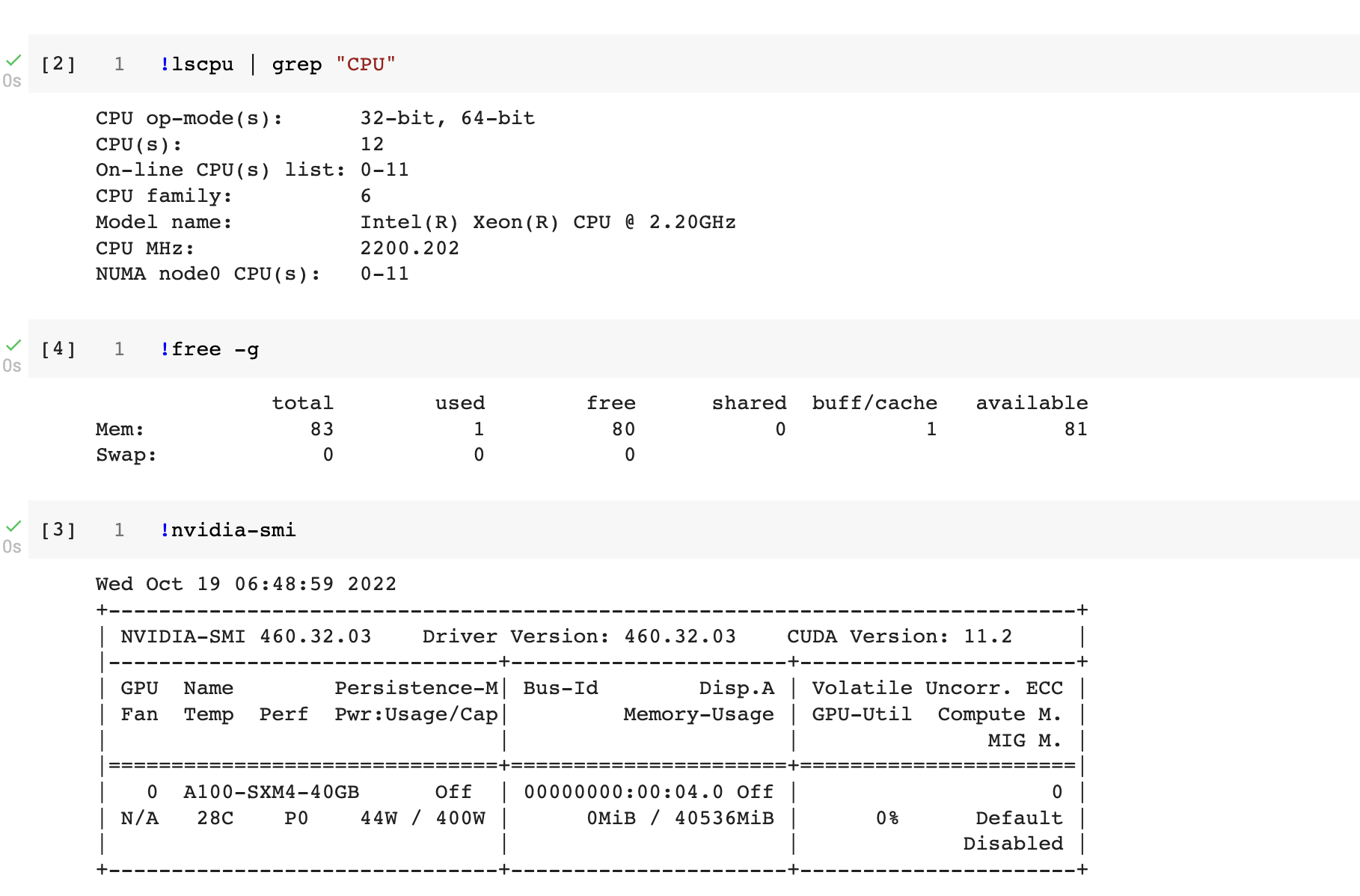
Google Drive(谷歌的云端磁盘)也通常需要搭配 Colab Pro 使用,可以根据自己的需求选择方案:
氪金完成后,我们就来说说如何高效地使用 Colab。
避免滥用
懂行的应该清楚,Colab 压根儿就是在做亏本生意,在大多数平台,9.9$ 可能只是 V100 1天左右的租用价格,而 Colab 是 1 个月。为了能持续地薅资本主义羊毛,我们应尽量避免滥用,做一个「守法」的用户,以下行为都属于滥用:
- 占着实例不用显卡
- 一个账号同时开多个实例
- 用计算资源做数据科学以外的事(挖矿?)
Colab 当然会对滥用行为做一些监控,如果某个账号经常滥用,则该账号可能会或多或少做点标记,导致实例经常无法开机或只能得到低配的硬件资源,因此知道如何避免滥用是非常有必要的。
可能有时候,不是有心要滥用实例,那如何做到不滥用呢?
不要一次性开多个实例
为了保证有持续的高配实例可用,我们最好保证同一时间只有一个 GPU 实例在运行,但有时候可能自己都不知道开了多个实例…
在 Colab 中,用户切换 Runtime 的时候,Colab 的行为实际上是「新开了一台实例」,而不是「关掉之前的实例,再开一台新的实例」,因此可能很多用户都不知道自己开了多台 GPU 实例。
所以在每次切换实例类型的时候,都需要手动关闭上一个开启的实例。
开了实例应尽快使用显卡
实例开启后应该尽可能快得使用显卡,否则可能会得到这样的警告信息:

如果长时间不使用显卡,实例有可能会被回收。因此,在使用 GPU 实例之前最好保证代码是可以运行的。如果实在想用 GPU 实例来开发,可以用下面的代码来做一个类似「占位」的操作:
import torch
placeholder = torch.rand(10, 512, 512).cuda()
运行上面的代码后,GPU 的显存就会被使用,因此不会被警告或收回实例。但这类似于用书占座的行为,我个人不推荐用这种方式。
用完之后主动关闭实例
在使用完之后,可能随手关闭浏览器就溜了;但其实关闭浏览器并不会立即关闭实例,Colab 有自己的监控,需要「过一段时间」才会关闭实例。而这段时间显卡是处于完全空闲的状态,所以在不用的时候,最好是能主动关掉实例,立即让 Colab 回收。
善用 Google Drive
Colab 的实例均为容器,每次使用实例都是起了一个新的容器,这带来的问题是数据无法在容器中持久化保存:在 Colab 中产生的所有本地磁盘的数据,都会在实例收回的那一刻被销毁,因此我们需要使用到 Google Drive,这是 Google 推出的云端硬盘,Colab 和 Drive 搭配使用是非常简单的,在 Colab 工具栏中就一个很大的挂载 Google Drive 的按钮,挂载之后就可以直接从 Colab 上将文件存放到 Google Drive 中。
使用 Colab 的第一步几乎都是「挂载 Google Drive」
下面分享一些比较好的实践。
数据集压缩、拷贝后再使用
不要直接从 Drive 中读数据来训练,因为 Colab 是云端硬盘,读写性能是非常差的,所以需要先将数据集从 Drive 中拷贝到本地磁盘中再使用。
其次,直接把目录从 Drive 中复制到 Colab 本地磁盘也很慢,正确的做法是在 Drive 中存放单个压缩文件,每次使用的时候,将这个压缩文件复制到 Colab 本地磁盘再进行解压。
写环境初始化脚本
因为 Colab 每次起新的实例都是默认环境,如果需要安装额外的包或添加数据集,最好是将这个过程自动化下来,写一个类似 init.sh 之类的脚本,每次启用实例只需要运行一次 bash /xxx/init.sh 就可以做好环境。