WeightedRandomSampler 的一点改进
通常我们很难遇到样本均衡的数据集,绝大部分的比赛任务或是真实场景,遇到的都是不均衡的数据集。在这种情况下,我们可能会使用到 Oversampling 的策略,也就是让数量较少的样本类别多次被 Sampler 选中,这样来解决不均衡的问题。
在 PyTorch 中,上面所说的 Sampler 就是 torch.utils.data.WeightedRandomSampler,那这个 Sampler 有什么需要改进的点呢?
看文档可以知道,该 Sampler 有一个 replacement 参数,这个参数默认是为 True 的。replacement 如果为 True,意味着一次循环中,某个样本可以被重复命中,而这本身就是我们使用 WeightedRandomSampler 的目的:重复多次选中少样本的类别。再进一步思考,为什么会设计一个 replacement 参数呢?
因为 Sampler 本身可以指定一个循环的迭代数量(由 num_samples 参数控制),假设总的样本有 10W,而某个用户不希望一轮(Epoch)训练就训练 10W 个样本,而是 1W 或者更小。在这样的场景下,replacement=False 是有意义的,他可以让每一轮中不出现重复的样本,而如果使用默认的 replacement=True,则是有可能在一轮中出现重复的样本的。
问题来了,对于上文讲的每一轮中不出现重复的样本,但在多个轮次之间,依然会有重复的样本产生,可能某个多数类别的样本在几轮下来一次都没被命中,而同类别的其他样本则多次被命中。
我们可以通过使用下面的这个改进之后的 ExhaustiveWeightedRandomSampler 来解决这个问题:
ExhaustiveWeightedRandomSampler
通过 ExhaustiveWeightedRandomSampler,我们可以尽可能地让某个权重的样本不重复采样,然后让其他权重的样本重复采样,这类似于给某一个特定 weight 的样本设置了 replacement=False,而对其他权重的样本设置 replacement=True。
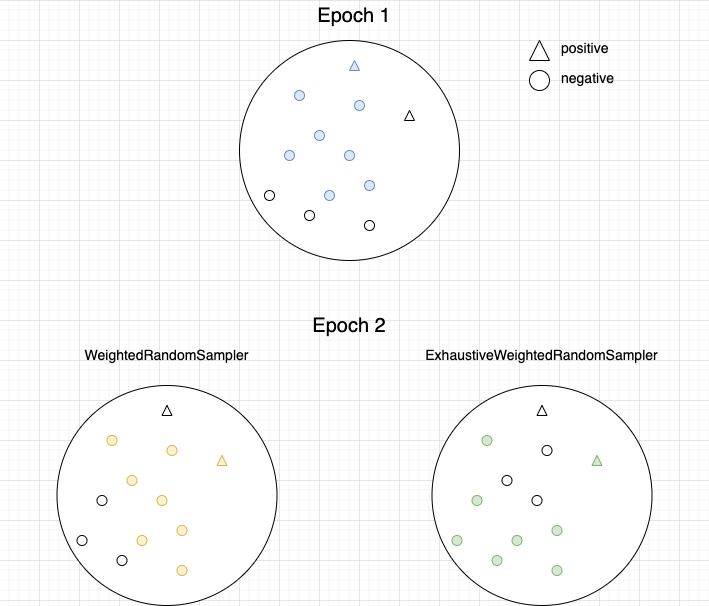
通过下面这种图来直观的比较两种 Sampler 的差异:
在上面的数据集中,有颜色的样本表示在当前的 Epoch 中被选中进行训练。我们可以看到对于 WeightedRandomSampler,左下角的两个样本在前两轮中都没有被训练到,而 ExhaustiveWeightedRandomSampler 在两轮中就遍历完了全部的样本。