
从源码理解 LoRA 微调原理
为什么看源码不看论文?因为论文上的一堆公式对数学渣来说是真不想看啊。
总的来说 LoRA 的代码很好理解,核心代码就十来行,读起来是轻松,因此本文篇幅相对较短。有效的方法通常都很简单。
官方源码
LoRA 的官方源码实现了 Conv,Linear,Embedding 的 LoRA 版本,本文用 Linear 来阐述其原理。
模型结构
对于普通的 Linear,其参数仅有 weight 和 bias,而 LoRA 多了两个 lora_A 和 lora_B,对应的代码逻辑如下:
class Linear(nn.Linear, LoRALayer):
def __init__( self, in_features: int, out_features: int, r: int = 0, alpha: int = 1):
# ...
self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features)))
self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r)))
self.scaling = alpha / r
因为本身继承自 nn.Linear,所以该模块还包含 self.weight 和 self.bias。可以看到 lora_A 和 lora_B 的维度分别是 (r, in_features) 和 (out_features, r),其中 r 是 LoRA 的超参数。
聪明的读者们应该已经意识到,lora_B @ lora_A 的 shape 正好等于 self.weight,也就是 (in_features, out_features),因此很容易联想到 LoRA 的实现中应该会有这样的操作:self.weight + lora_B @ lora_A,事实也正是如此。
注意到这里的还有一个超参数 alpha,他处以 r 会得到一个 self.scaling 浮点数,这个数在接下来的计算中会用到。
因此 r 在这里有两个作用:
- 在
lora_B @ lora_A中充当了类似 hidden dim 的作用。 - 和
alpha一起获得了一个scaling参数。
如果对于一个 1024 x 1024 的 Linear 层(不算 bias 共 1,048,576 个参数),如果 r = 64,那么增加的参数量为 1024 * 64 + 64 * 1024 = 131,072,这个参数量仅是原参数量的 1/8。
训练过程
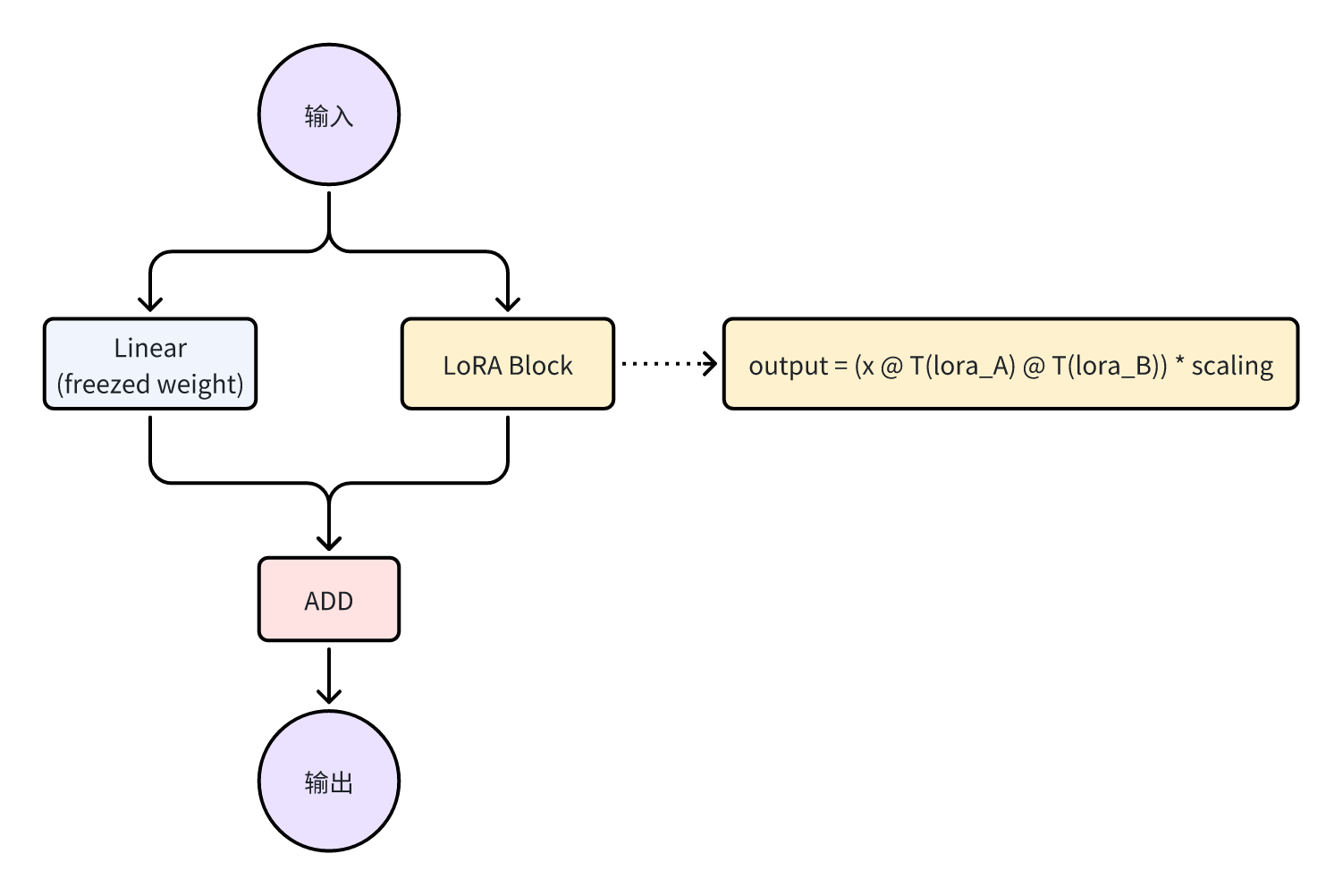
图应该已经很清楚了,X 分别过 self.weight 和 lora_B @ lora_A,将输出相加后得到结果。不过注意 Linear 的参数是被固定的,并不参与训练优化,训练过程中仅优化 lora_A 和 lora_B。
抬出代码:
def forward(self, x: torch.Tensor):
if training:
x1 = F.linear(x, T(self.weight), bias=self.bias)
x2 = dropout(x) @ T(self.lora_A) @ T(self.lora_B) * self.scaling # 这里还有个 dropout
x = x1 + x2
else:
# 推断的逻辑,稍后给出
return x
推理过程
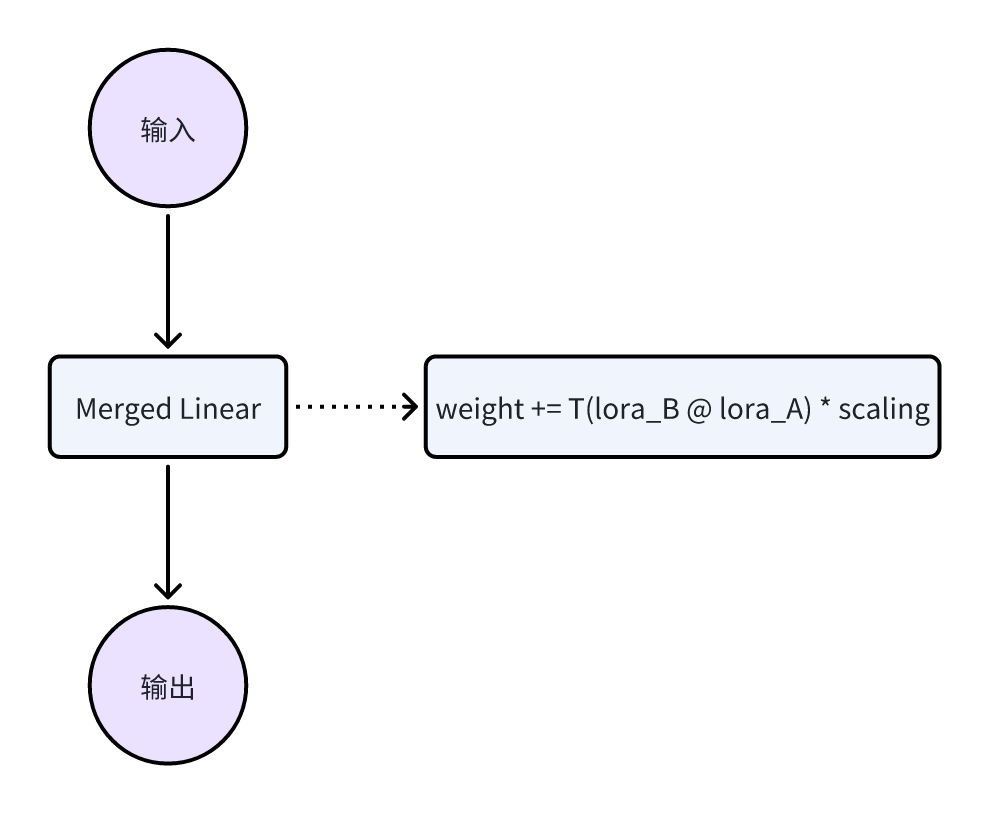
在推断之前,我们都会调用 model.eval() 方法,而该方法会触发 LoRA 模型的一个 merge 操作,如代码所示:
self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling
也就是聪明的读者们早就猜到的加法操作,这样,相当于把 lora_B 和 lora_A 的所有信息,「融合」到了 self.weight 中。融合之后,推理过程就跟一般的 Linear 一模一样了。
Hugging Face PEFT
对于大模型 LoRA 微调,用更多是用 Hugging Face 的 PEFT 来做。下面来看看在大模型微调中 LoRA 是如何做的。先看一下官方的使用 Demo:
from transformers import AutoModelForCausalLM
from peft import get_peft_model, LoraConfig, TaskType
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen1.5-0.5B")
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=64,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["q_proj", "v_proj"]
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()trainable params: 6,291,456 || all params: 470,279,168 || trainable%: 1.3378130327899194
LoraConfig 中的 r 和 lora_alpha 等参数上文都已经讲过,主要关注到 target_modules,原始大模型 QWen 中的 q_proj 和 v_proj 是 Linear 层,而 get_peft_model 会自动将其转换为 LoRA 层。
注意到 target_modules 参数,这个参数标识需要被替换为 LoRA 的模块名。
下面为 inject 前后两个模型的结构对比,左边是普通模型,右边是 LoRA 模型。
可以看出 LoRA 模型中的 q_proj 和 v_proj 都被修改为了 lora.Linear,并且增加了 lora_dropout,lora_A 和 lora_B 等参数。
QLoRA
QLoRA 是在 LoRA 的基础上,加上了模型量化。QLoRA 允许主模型是一个量化模型,因为主模型往往参数都非常多,加上量化后会极大得降低主模型对资源的要求。
QLoRA 论文上主要有三个贡献:
- 4-bit NormalFloat (NF4) quantization,一种新的量化类型
- Double Quantization(DQ),一种新的量化方法
- Paged Optimizers,一种针对 NVIDIA 的硬件上的优化方法
QLoRA 主要的使用方法跟 LoRA 的区别并不大,仅是多了两个参数 bnb_4bit_quant_type 和 bnb_4bit_use_double_quant,这都是多了一些参数控制,下面是例子:
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)QLoRA 的实现位于 bitsandbytes 中,核心实现都是 CUDA C++ ,这里就不展开讨论了。
总结
LoRA 使用了一个简单的加法操作,将原有的 weight 和 lora_B @ lora_A 相加,通过仅对 lora_* 做训练,来极大的减少需要优化的参数(单层降低 1/8,全部大模型的话大约能缩减到 1%,因为并不是所有层都被转为 LoRA)。
核心参数说明
-
r 参数指定了
lora_B和lora_A的hidden dim,因为添加的参数量为in_features * r + r * out_features,因此其越大则表示所添加的训练参数越多。 -
alpha 参数是一个缩放参数,
lora_B @ lora_A的结果会乘以alpha / r,这个参数可以用来控制lora_B @ lora_A对原模型的影响程度。其越大则表示对对原模型的影响越大。 -
dropout 在输入上加上的
dropout,可参考训练过程中的代码。 - target_modules 这是 PEFT 中的一个参数,指定了需要被替换为 LoRA 的模块名。