有关人脸重建工作的梳理之一 —— 神经辐射场 NeRF
最近工作中涉及到实时的数字人渲染,因此梳理了一下近些年的工作,对于作者来说,几乎全是新鲜事物:),从平常搜索的过程中发现这个方向热度非常高,主要原因是非常适合商业的落地(就是很能赚钱)。本文主要是对这个方向的一些工作进行梳理,以及对 NeRF 的浅薄理解。
近些年的工作梳理
时下 2D 图像技术盛行,人脸重建最容易想到的就是极致得使用 2D 图像相关的技术来实现,例如通过音频、文字甚至文字的感情来产生关键点或图像,然后再通过图像的方式渲染人脸。这种方法主要的问题是需要在渲染速度和质量上做很大的取舍。一般来说,直接替换人的嘴部区域会导致图像非常割裂,需要再用到的一些面部修复技术来二次精修,这样导致整个渲染过程非常慢。代表的工作有基于 GAN 的 LibGan: Towards Automatic Face-to-Face Translation,使用 lipsync 监督的 Wav2Lip: A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild,基于 Diffusion 的 Diff2Lip: Audio Conditioned Diffusion Models for Lip-Synchronization。
而最近更流行的方向,是基于神经辐射场(Neural Radiance Fields, NeRF)的方法(NeRF YYDS!)。NeRF 通过体积渲染(Volume Rendering)的方式,可以使整个脸部细节保留得更完整,并且可以像 3D 游戏中创建人物时的捏脸的方式一样去捏 2D 图像,代表性的工作是:Dynamic NeRF: Dynamic Neural Radiance Fields。既然可以捏 2D 的头像,那么通过文字或语音驱动嘴形也就顺理成章了,例如AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis。ADNeRF 可以通过音频或文字渲染出高质量的人脸说话视频,但其本身的训练和推理过程都非常耗时(因为 NeRF 本身的原因),但好在有一系列的工作来加速 NeRF 的训练和推理过程,这使得实时渲染高质量的数字人成为可能。现在,终于可以重磅请出 RAD-NeRF: Real-time Neural Talking Portrait Synthesis,该工作可以实现实时的高质量人物渲染,这对于游戏、电影、直播等领域都有着非常大的应用前景。后续还有一些其他工作,几乎都是基于 RAD-NeRF 的改进,例如 GeneFace: Generalized and High-Fidelity Audio-Driven 3D Talking Face Synthesis。
NeRF 的工作原理
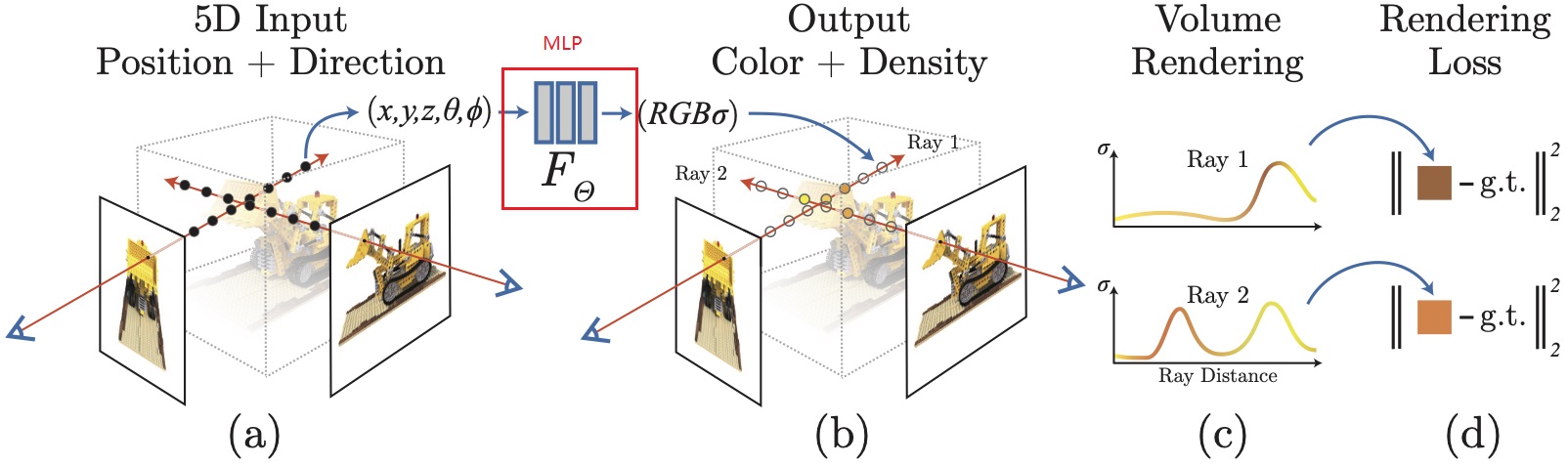
NeRF 主要用于 3D 重建。给定一个物体,通过从不同方向上对该问题进行拍摄来获取一组图片,然后使用这组图片数据来对该物体进行 3D 建模,而该模型不同于传统的 3D 模型(例如 Blender 中的模型),而是一个神经网络(由 MLP 组成,大小一般在 100MB 以内)。
先说推理
NeRF 由两个部分组成:
- 3D 模型隐式表达(神经网络)
- 体渲染(Volume Rendering)
神经网络
NeRF 使用一个神经网络来「存储」一个 3D 模型,这个神经网络的作用是,给定一个视角(摄像机的位置和方向等)和空间点的位置(空间的某一个点),NeRF 可以推理出该点的信息(颜色和密度)。
更具体一点: NeRF 的输入是一个五元组(x, y, z theta, phi),其中(x, y, z)表示真实空间 3D 坐标系中的一个点,(theta, phi)表示此刻观察该点的摄像头位置信息。输出为该点的颜色(rgb值)和体积密度(sigma)。体积密度主要在第二步的体渲染中会用到,现在可以暂时将他视作为该点的一个权重,要更直观的解释的话,可以把他看作透明度。(输入除了 5 元组,其实还有位置信息编码,但这不影响我们理解 NeRF 原理,因此不做介绍了)。
体渲染
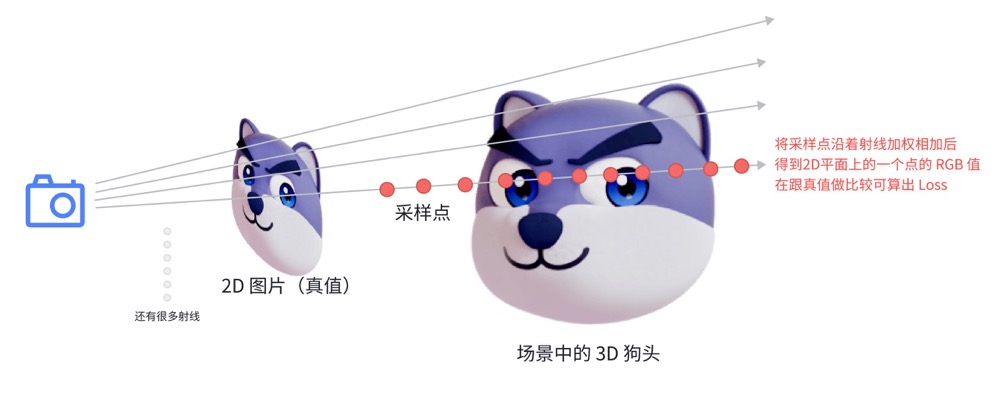
体渲染就是将 3D 空间中的所有点渲染成一个 2D 图片。因为在第一步中,我们可以得到在某个视角下的所有空间点的 RGB 和密度信息,体渲染则是将这些信息转换成 2D 图像。体渲染的过程是一个积分过程,即同一个视线(可理解为观测点到 2D 图像上某个像素的连线,后问有详细说明)上的对每个像素点进行积分,得到该视线对应 2D 图像上某个点的颜色信息。形象的解释可以想象成把整个空间的信息沿着视线的方向去拍扁(或者说是投影),拍扁后的 2D 图片就是渲染结果。
体积密度在这里会发挥作用:在体渲染的过程中,我们需要对每个像素点进行积分,而这个积分的权重就是体积密度。体积密度越大,说明这个点越重要,因此在积分的过程中,这个点的权重就越大(其实就是加权求和)。
现在,我们已经可以通过输入某一个视角信息,就得到一个 2D 图像,完成了 3D 渲染的工作。
训练
训练就很简单了,因为在推理过程中,已经得到了一个 2D 图像,那么直接可以将这个 2D 图像和真实的 2D 图像进行对比,算 MSE 损失即可。注意第一步神经网络和第二步体渲染都是可导的,因此整个过程是可导的,可以直接端到端地训练神经网络。
关于 z 是如何选择的? 因为输入是一个空间信息,而我们从拍摄到的图片仅能获取到 2D 的信息,那么这里 z 的输入应该是什么?
在上面的介绍中,有一个重要的信息没有提及,就是输入的 x, y, z 是如何选择的。特别是 z,因为我们的数据是图片,图片是 2D 的,只能拿到 x, y,那么 z 是如何选择的呢?这里需要引出一个概念:射线投射(Ray Casting)。
简单来说:从拍摄位置,到 2D 图像上的某个点,就可以在 3D 空间中确定一条射线,也就是上文提到的视线(起点是相机位置,理论上没有终点),而 (x, y, z) 就是我们在这条线上采样一些点(因为这条线是空间中的线,因此点的三维空间坐标也是可以确定的,也就是 z 也是确定的),只是采样的方法有很多种,例如均匀采样、随机采样等等。采样的方式也关系到模型的性能。下面是 ChatGPT 的解释:
给定一个2D图像上的像素点,可以根据相机模型反向投射出一条3D空间中的射线。这条射线从相机的中心出发,通过像素点对应的“视窗”上的点,延伸到场景中。通过改变射线上点的深度(即 z 坐标),可以在3D空间中采样不同的点。这种方法称为射线投射(ray casting)。
总结
字太多了,放个狗头吧: