图神经网络初见(一) —— PyTorch Geometric 数据集逻辑梳理
本文主要梳理一下 PyTorch Geometric(下文简称 PyG)中数据集部分的逻辑。
PyG 中使用 torch_geometric.data.Dataset 来表示一个数据集,一个数据集可包含多个图,每个图由 torch_geometric.data.Data 对象表示。torch_geometric.data.Data 对象包含了图的节点、边、特征等信息,以及图的标签等信息。下面我们详细得了解其中的细节。
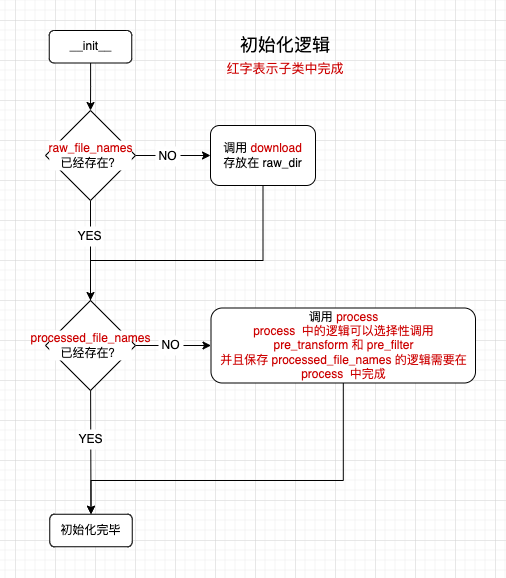
初始化
初始化数据集会选择性地做两件事:
- 下载数据集,将数据集的原始数据下载到本地某个目录中
self.raw_dir。 - 预处理数据集,调用
process方法对数据集进行预处理,该方法需要用户自己实现。这里的「预处理」实际上指的是将原始数据集处理为含有torch_geometric.data.Data(下文以Data代称)的一个列表,而Data则是torch_geometric中用于表达一个图的基本数据结构。关于process以及Data对象,下面将详细说明。
预处理
预处理的逻辑位于 torch_geometric.data.Dataset.process 方法中。
在 process 方法中,用户需要将原始数据集处理成图数据结构,每个图用一个 Data 对象表示。为了避免每次读取数据都要做相同的处理,我们还需要将这些 Data 对象存放到硬盘中。
所有处理好的 Data 对象应该可以被索引,因此通常需要将 Data 存储在一个列表中。如果内存不足,每个 Data 可以存储在硬盘中,文件名带有索引即可。
Data 对象
定义位于:torch_geometric.data.Data。Data 表示了一张图,有两个核心的属性:
-
x -> [num_nodes, num_node_features]所有点的特征矩阵。 -
edge_index -> [2, num_edges]表示所有的边,邻接矩阵的一种简单的表现方式。
通过上述两个属性,就可以确定一张图。在 torch_geometric 中,大多数相关的模型都需要同时传入这两个属性作为输入。因此,这两个属性通常是必不可少的。
其他可选的属性:
-
edge_attr -> [num_edges, num_edge_features]表示边特征,即边的属性,例如在社交网络中人与人的关系特征,或是节点之间的距离等。并不是所有的模型都支持处理边的特征,可以通过model.supports_edge_attr来确认模型是否支持边特征。因此,这应该是一个可选特征。 -
pos -> [num_nodes, 3]表示每个节点在空间中的坐标。对于一些 Graph 模型,除了需要节点的特征和关系之外,还需要节点在空间中的位置信息,例如处理点云(Point Cloud)时需要知道点的空间位置信息。当然,除了这种用法之外,还可以将节点的空间信息编码为edge_attr并传入一般的模型中。
获取样本 get 方法
跟 torch.utils.data.Dataloader 的 __getitem__ 类似,用户需要定一个 get 方法来获取单个样本,该方法的签名如下:
def get(self, idx: int) -> Data
数据预处理 & 增强
PyG 默认提供了一些数据变换的方法,它们位于 torch_geometric.transforms 中。可以使用这些方法来对 Data 对象进行各种变换。
在选择数据变换时,我们需要考虑该变换是「预处理」还是「随机增强」。通常将原始数据处理为 Data 的集合都是一个耗时的过程,因此 Dataset 的初始化被设计为带有缓存的逻辑。Dataset 的初始化方法提供两个参数,pre_transform 和 transform。对于「预处理」的变换,应该传入 pre_transform,而对于在线的随机增强,则传给 transform。
💡 虽然 pre_transform 和 transform 是基类
Dataset的属性,但它们都需要用户在子类的 process 和 get 方法中手动调用才会生效。
Batching
图的批处理与图像或序列不同。在图像和序列中,通常使用 padding 或 resize 将不同尺寸、长短的样本堆叠在一起,但这种方法无法对图做类似的操作。
图有一个特性,如果节点之间没有连接,则它们不会相互传递消息。因此可以直接将几个图堆叠成一个超图(HyperGraph),而这个超图中的每个小图就像一座孤岛,彼此之间没有连接关系。因为堆叠起来的大图仍然是一张「图」,在结构上可以直接用于所有图模型,因此在模型层面也无需做任何改动。
torch_geometric.loader.DataLoader 会自动完成上述的 batching 操作。它的实现只是替换了 torch::DataLoader 的 collate 参数,因此其他的参数与 torch::DataLoader 保持一致。collate 中的逻辑也并不复杂,只需要将每个 Data 的 x 属性直接进行 cat 操作(相当于直接 cat 节点信息),而 edge_index 属性在进行 cat 操作的同时加上一个偏移即可,其偏移量就是已经被 stack 的节点数量。
下面是 batching 数据的一些打印信息:
train_dataset[0]
#=> Data(x=[2645, 2], edge_index=[2, 5198], y=[1])
train_loader = iter(DataLoader(train_dataset, batch_size=2))
next(train_loader)
#=> DataBatch(x=[3680, 2], edge_index=[2, 7162], y=[2], batch=[3680], ptr=[3])
next(train_loader)
#=> DataBatch(x=[15985, 2], edge_index=[2, 31879], y=[2], batch=[15985], ptr=[3])
next(train_loader)
#=> DataBatch(x=[3910, 2], edge_index=[2, 7624], y=[2], batch=[3910], ptr=[3])
总结
torch_geometric 的 Dataset 在 PyTorch 的基础上增加了 download 和 process 方法。这些方法的目的是让用户将原始数据集转换为 Data 对象的集合,并做缓存。
Data 对象是 torch_geometric 的一个非常核心的接口。我们用 Data 来表示一张图,其中 Data.x 表示节点信息,Data.edge_index 表示节点与节点的邻接信息。
Batching 几乎不需要用户写代码, torch_geometric 的 DataLoader 会自动完成该工作。