
RSNA 2023 #4 方案解析 —— 多图特征融合
本文是笔者在复盘比赛后的总结和输出,并不是原英文方案的直接翻译。因此可能存在一些主观理解或偏差。
总览
这个方案出自三位 Kaggle GrandMaster,并且与很多「暴力出奇迹」式的 Ensemble 模型不同,它采用了独特的架构设计。此外,在细节处理上也非常到位,该方案名列第四可以说实至名归。
由于数据集中的图片尺寸较大,而用于癌症判断的特征非常微小,因此该方案首先对图片进行了仔细的 Resize 研究,并发现某些 Resize 方法可能会导致关键特征损坏。
此外,由于本次比赛为多张图片对应单个标签,如何合理利用多个图像是获胜的关键,因此方案作者还提出了两种多图片融合的方法。实际上,在许多比赛中,图片融合技巧都非常实用,并且可以被视为一种相对通用的解决方案。
预处理
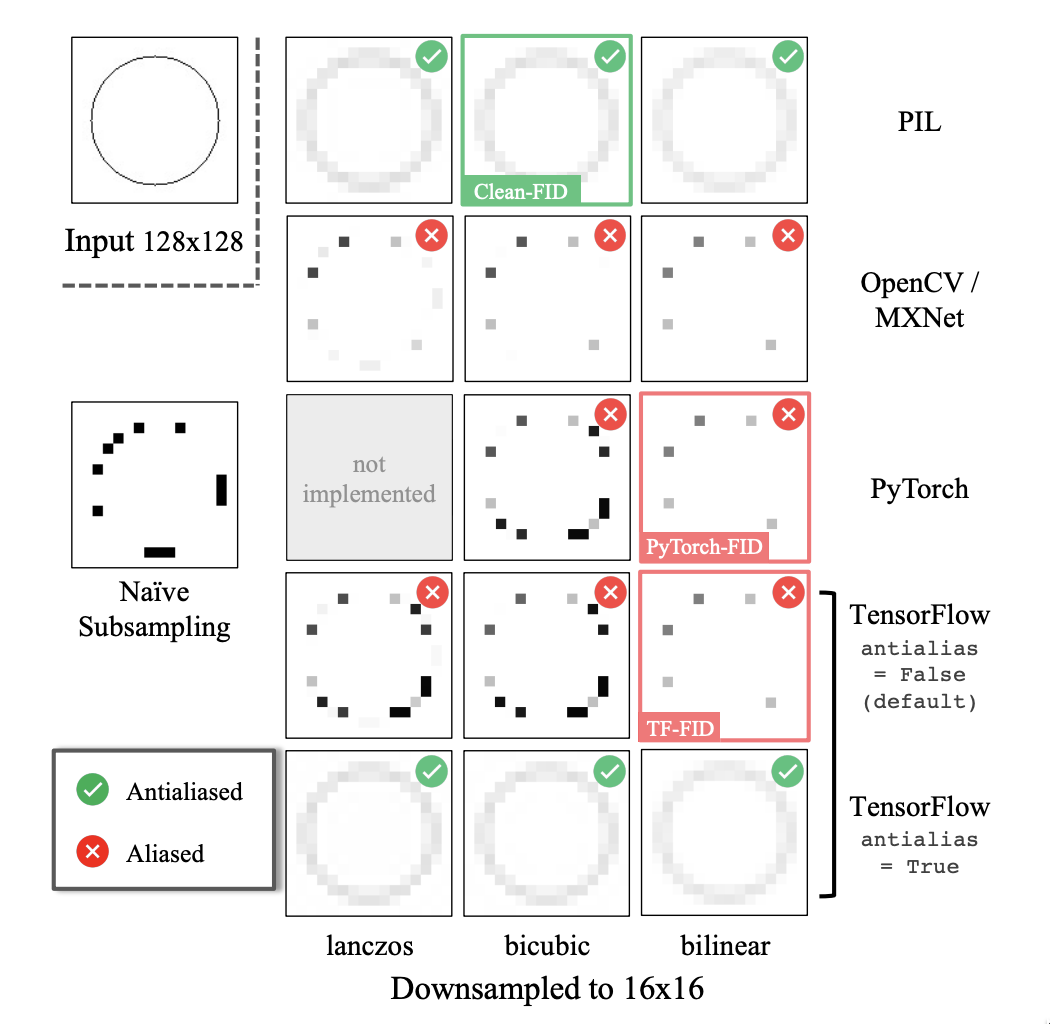
由于癌症特征通常在整个 X 光影像图片上非常微小,所以针对 resize 也做了优化。很多 resize 方法可能会损失掉细小的局部特征,例如下图所示的仅包含一个圆环的图片。仅有 PIL 的 Image.resize 和 TensorFlow 的 tf.image.resize(antialias=True) 两种方法能成功保留完整的圆环。该方法取自这篇论文:On Aliased Resizing and Surprising Subtleties in GAN Evaluation。
其次,为了确保不丢失关键的细微局部特征,作者将部分图像增强处理放在 resize 操作之前进行,尽管这会显著增加计算量。其 Augmentation 顺序如下:
- 读取原始图片
- vflip, hflip,transpose, shift, scale, rotate, grid distortion & affine
- resize
- random grid shuffle & coarse dropout
- normalization
图片融合一
先看一下原文的流程图:
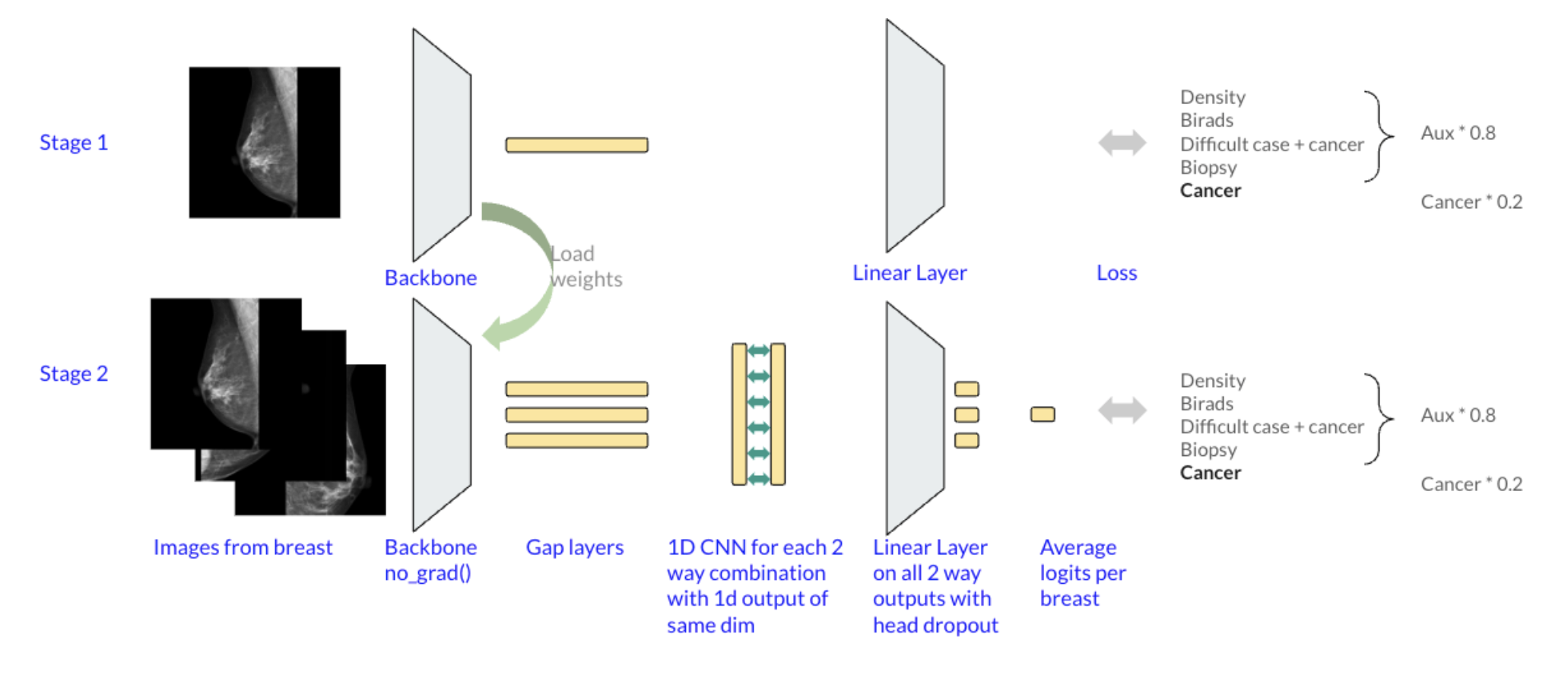
流程图中包含了多个额外的损失,但这并非本文的重点,我们将关注两个训练步骤(Stage):
第一步:单图训练,得到特征提取器
先不管多张图片对应单个标签的事儿,我们先将每张图片都视为一个单独的样本,并以此训练模型(这也是绝大部分人的做法,包括笔者自己)。这一步的目的,这一步的主要目的是获得一个优秀的骨干网络作为第二步中特征提取器使用。
在实际应用中,最好能够在这一步就训练出优秀的模型,以此确保我们能够获得高质量的骨干模型,因为这对后续步骤的影响非常大。
第二步:多图训练,使用 1D-CNN 做图片融合
固定第一步的 backbone 作为特征提取器,将同一病人的多张图片输入到模型中(利用 batch_size 的维度,可以同时提取到多个图片的特征),然后,使用 1D-CNN 来融合提取到的特征,具体步骤如下:
- 将同一个 patient 的 N 张图片 stack 在一起(在 bs 那一维),使用 stage1 的模型提取向量特征(过 Pooling 层),这样会得到 shape 为 N x dim 的 features。
- 将 N 个 feature 两两组合(stack),共有 M(Cn2)个组合,则会获得 M x dim x 2 的组合特征。
- 将组合的特征过
Conv1d(kernel_size=2, padding=0),输出为 M x dim,这 M 个向量特征既是这一组图片的深度特征,也能表达图片之间的关联性。 - 第三步获得的特征过一个全链接层,获得 M x 2 的输出,求均值后得到 (2, ) 的预测值,分别表示病人的左右乳房患病概率。
具体的代码如下(为了演示,下面是简化后的代码,只处理单个病人的多个图片:):
import torch
from itertools import combinations
class MultiImageFusion(torch.nn.Module):
def __init__(self):
super().__init__()
self.backbone = timm.create_model('resnet18', pretrained=False)
self.conv1d = torch.nn.Conv1d(512, 512, kernel_size=2, padding=0, bias=False)
self.classifier = torch.nn.Linear(512, 1)
def forward(self, x):
x = self.backbone.forward_features(x)
x = torch.nn.functional.adaptive_max_pool2d(x, 1).flatten(1)
# 在 bs 维度进行两两组合,比如如果 x.shape 为 (4 x 512),那么组合后的
# shape 是 6 x 512 x 2,因为 4 个特征一共有 6 种组合
x = torch.stack([torch.stack(couple, dim=1) for couple in combinations(x, 2)])
x = self.conv1d(x).flatten(1)
logits = self.classifier(x)
# 因为 logits 为 6 种 feature 组合的结果,这里求均值后得到
# 这个病人的多张图片聚合后的 logit
return logits.mean()
# 假设每个病人有 4 张图片,可以使用 batch_size 维度来组织单个病人的图片。
multi_images = torch.rand(4, 3, 224, 224)
model = MultiImageFusion()
res = model(multi_images)
print(res) # => tensor(1.0893, grad_fn=<MeanBackward0>)从输入输出的角度来看,该模型接受 6 张图片作为输入(batch size = 6),并输出单个 logit,实现了多张图片的融合。需要注意的是,在使用该模型时无需训练 backbone(freeze backbone)。
图片融合二
除了第一种 1D-CNN 的融合,作者还提出了 transformer 的融合方式。整个架构如下图所示:
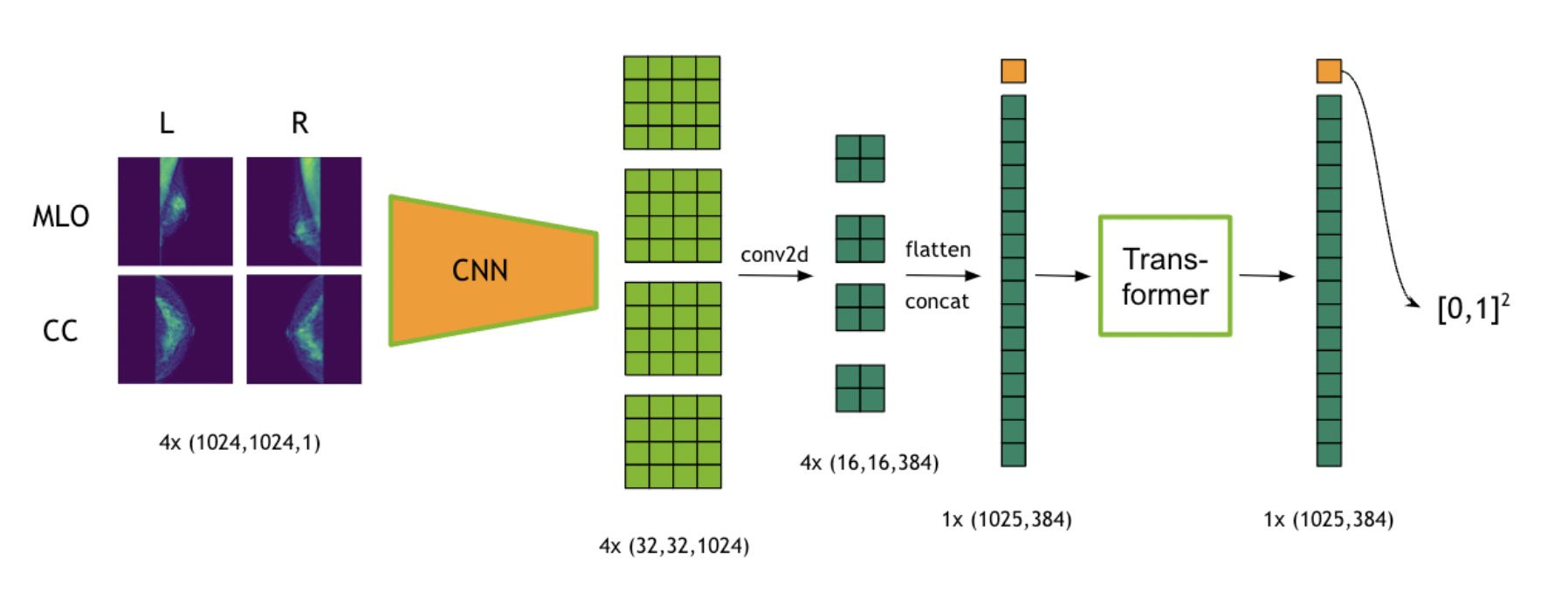
详细的流程如下:
- 选择某个病人的 4 张图片(若病人图片数量多于 4 张,则随机选取)。
- 这四张图片 stack 成一个 batch,纬度是
4 x height x width x dim,喂到之前训练的 CNN 模型中,得到一个 feature map,纬度4 x feat_h x feat_w x feature_dim。 - 将 feature map 在 feat_h 和 feat_w 纬度上打平然后拼接,得到
1 x (feat_h * feat_w) x feature_dim的向量特征。 - 上面的向量特征可直接喂给处理时序的模型,这里选择的是 transformer,然后预测最后的结果。
简化的实现:
import torch
class MultiImageFusionV2(torch.nn.Module):
def __init__(self):
super().__init__()
self.backbone = timm.create_model('resnet18', pretrained=False)
self.conv2d = torch.nn.Conv2d(512, 384, kernel_size=2, stride=2, bias=False)
self.transformer = torch.nn.TransformerEncoder(
torch.nn.TransformerEncoderLayer(d_model=384, nhead=8),
num_layers=4,
)
self.fc = torch.nn.Linear(384, 1)
def forward(self, x):
x = self.backbone.forward_features(x) # 4 x 512 x 32 x 32
x = self.conv2d(x) # 4 x 384 x 16 x 16
x = x.permute(0, 2, 3, 1).contiguous().view(-1, 384).unsqueeze(0) # 1 x 1024 x 384
x = self.transformer(x)
return self.fc(x[:, 0, :])
# 假设单个病人有 4 张图片,用 batch_size 维度来放置单个病人的图片
multi_images = torch.rand(4, 3, 1024, 1024)
model = MultiImageFusionV2()
res = model(multi_images)
print(res) # => tensor([[-1.0924]], grad_fn=<AddmmBackward0>)这里用一个 kernel_size=2 stride=2 的二维卷积来进一步将 feature map 分为 256 个 patch,因为输入为同一个患者的 4 张图片,flatten 之后会得到 1024 个 patch。这些 patch 可视为一个 sequence,并且可以作为输入传递给 transformer 模块,需要注意的是,在此之前需要 unsqueeze(0) 来添加 batch_size 的维度。
总结
这套方案最为核心的贡献可以概括如下:
- 对于需要识别的特征很小的情况,预处理的过程需要非常谨慎,尤其是对于非随机的过程,比如 Downsamping Resizing 的操作。
- 合理利用 batch 维度进行多图片的聚合是有益的,不必局限于 batch 中的元素一定代表单个样本。