
RSNA 2023 #6 方案解析 —— CAM 的妙用
该系列其他文章
Kaggle RSNA 乳腺癌检测比赛复盘(一)—— 赛题介绍和自我总结
Kaggle RSNA 乳腺癌检测比赛复盘(二)—— #4:多图特征融合
Kaggle RSNA 乳腺癌检测比赛复盘(三)—— #6:CAM 的妙用
在神经网络可解释性的研究中,常常使用 CAM(Class Activation Map)技术。此外,CAM 还被广泛应用于弱标签分割问题,即仅给出图片级别的类别信息,而需要预测像素点的类别。本次比赛是一个相对简单的图像分类问题,在该方案中也引入了 CAM 技术。下面我们来看一下具体实现方法。
多图特征融合(Stage 1)
与第四名的方案一样,比赛的关键点依然是多个图像如何做特征融合,作为第六名的方案,依然也运用到了这个技术,但做法又与之不同。这个方案采用了更直接和简单的做法。
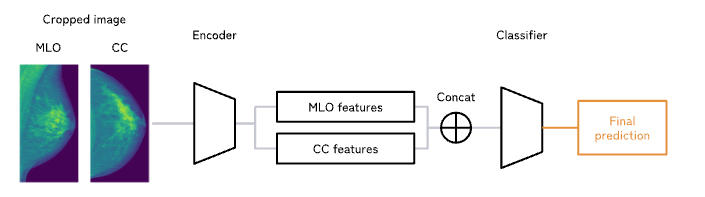
融合的流程非常的简单:就是直接将多张图片的特征向量 Cat 起来,然后再接一个全连接层获得多张图片的单个输出结果。
在原作者提供的源码可以找到融合的逻辑,但源码中地细节比较多,不太便于理解和演示,这里给出一个简单的版本,基于这个版本做改进也是完全可行的。
作者的源码中可以学习的东西挺多的,感兴趣的小伙伴可以深挖一下。
import torch
import timm
class MultiFeaturesFusion(torch.nn.Module):
def __init__(self):
super().__init__()
self.backbone = timm.create_model('resnet18')
self.cls = torch.nn.Linear(1024, 1)
def forward(self, x):
bs, n_imgs, ch, h, w = x.shape
x = x.view(bs * n_imgs, ch, h, w) # 把前两维打平
x = self.backbone.forward_features(x) # (bs * n_imgs) x ch' x h' x w'
x = torch.nn.functional.adaptive_avg_pool2d(x, 1) # (bs * n_imgs) x ch' x 1 x 1
x = x.view(bs, n_imgs, -1) # bs x n_imgs x ch'
x = torch.flatten(x, start_dim=1) # bs x (ch' * n_imgs) ,这里 ch' * n_imgs 则为多个图片特征的连接
return self.cls(x)
images = torch.rand(8, 2, 3, 256, 256)
model = MultiFeaturesFusion()
print(model(images).shape) # => torch.Size([8, 1]CAM(Stage 2)
接下来就是这篇文章的主角了,Class Activation Map。CAM 具体就不赘述了,这里主要说一下在这个比赛中的应用。先看结构图:
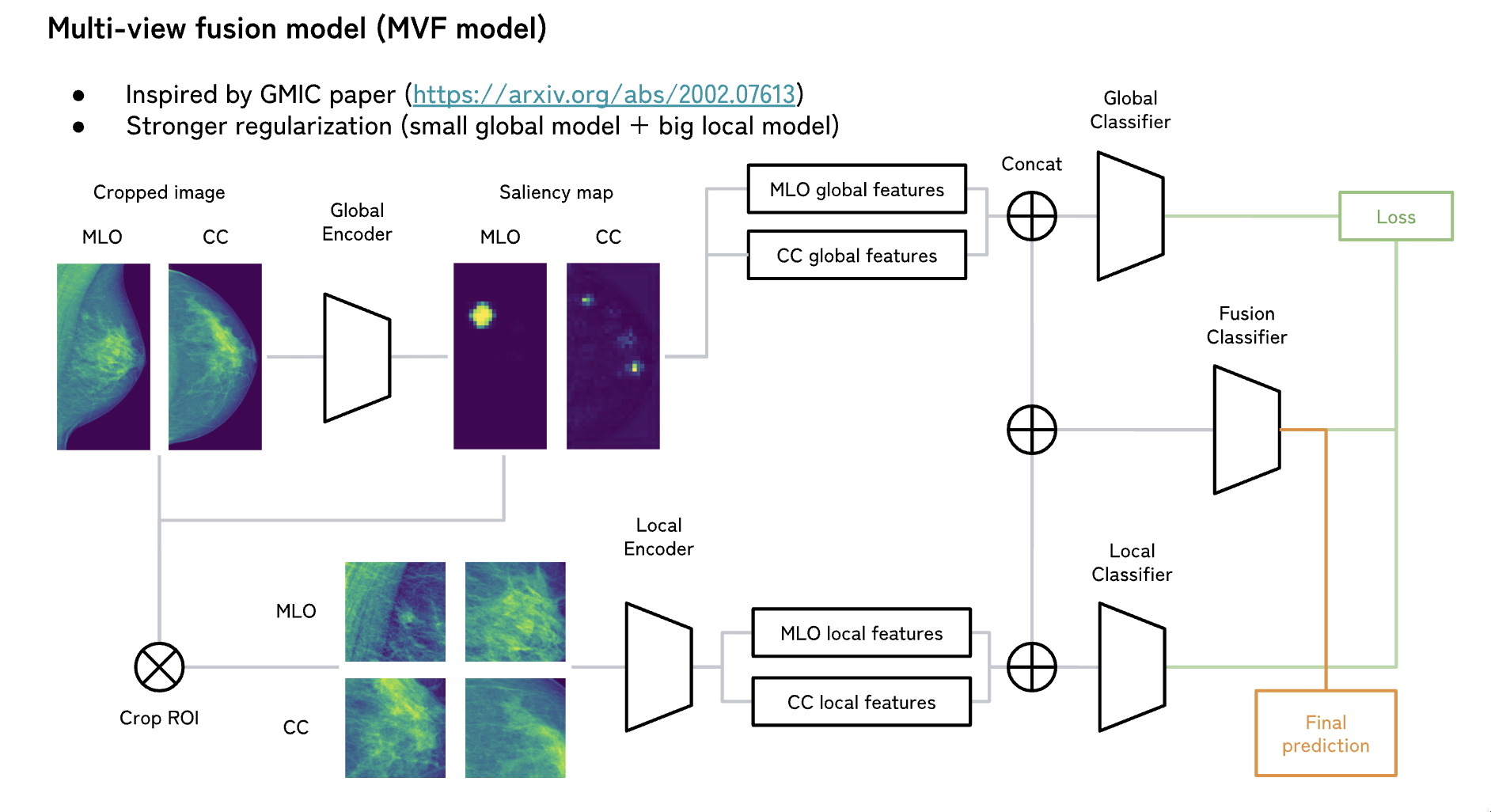
详细的步骤如下:
- 通过第一步的模型获取到 CAM。
- 通过 CAM 从原图上获取到感兴趣区域(Region of Interest,RoI),利用 CAM 切 RoI 的办法有很多,下面说一下原作所用的方法:
- 将原图切成 N 个边长为 M 的方形切片。
- 每个方形切片找到对应的 CAM 的切片,sum 该 CAM 切片后获得该切片的 CAM 得分。
- 用得分 sort 出高分切片,取前 L 个切片作为 RoI。
- 将若干个 RoI 过 backbone,获取到特征作为「局部特征」(Local Feature)。
- 第一步的 CAM 也可以继续前向以获得「全局特征」(Global Feature)。
- 把 Local Feature 和 Global Feature 连起来,做为 Fusion Feature,用来做最后的预测。
下面是笔者复现的「简化后」的代码,因为整个流程确实是比较复杂的,中间也利用到了一些矩阵索引的高级特性,所以可能不会非常直观,我也尽量加了注释以便于理解。另外代码是可以直接复制粘贴运行的,建议手动单步调试以加深理解。
为了使代码尽量简单,下面的实现并没有包含 Stage 1 中的多图特征融合逻辑。
import torch
class CamFeatureFusion(torch.nn.Module):
def __init__(self):
super().__init__()
self.backbone = timm.create_model('resnet18')
self.fc = torch.nn.Linear(2560, 1)
self.extract_cam = torch.nn.Conv2d(512, 1, kernel_size=1, stride=1, bias=False)
self.crop_size = 32
self.roi_num = 4
def extract_roi(self, x, cam):
bs, dim, h, w = x.shape
cam = F.interpolate(cam, size=x.shape[-2:], mode='bilinear', align_corners=False)
cam = cam.sigmoid()
# 将输入和cam在dim上连起来,这样只需要对单个 Tensor 做 Crop 操作
x = torch.cat([x, cam], dim=1)
# x_cropped: [4, 4, 7, 32, 7, 32]
x_cropped = x.view(bs, dim + 1, h // self.crop_size, self.crop_size, w // self.crop_size, self.crop_size)
# x_cropped 调整为:[4, 4, 7, 7, 32, 32]
x_cropped = x_cropped.permute(0, 1, 2, 4, 3, 5).contiguous()
# x_cropped 调整为:[4, 4, 49, 32, 32]
x_cropped = x_cropped.view(bs, dim + 1, -1, self.crop_size, self.crop_size)
score = x_cropped[:, -1].sum(dim=(2, 3))
_, indices = score.sort(dim=1, descending=True)
x_cropped = x_cropped[:, :-1].permute(0, 2, 1, 3, 4).contiguous()
# 使用 advanced indexing
return x_cropped[torch.arange(4)[:, None], indices][:, :self.roi_num]
def forward_roi_features(self, rois):
bs, roi_num, dim, h, w = rois.shape
rois = rois.reshape(bs * roi_num, dim, h, w)
feature_maps = self.backbone.forward_features(rois)
return feature_maps.view(bs, roi_num, -1, feature_maps.shape[-2], feature_maps.shape[-1])
def forward(self, x):
feature_maps = self.backbone.forward_features(x)
cam = self.extract_cam(feature_maps) # [B, 1, H', W']
rois = self.extract_roi(x, cam) # [B, self.roi_num, C, self.crop_size, self.crop_size]
roi_feature_maps = self.forward_roi_features(rois)
# pooling 然后 concat roi_features_maps 和 feature_maps
features = torch.mean(feature_maps, dim=(2, 3), keepdim=False)
roi_features = torch.mean(roi_feature_maps, dim=(3, 4), keepdim=False).flatten(start_dim=1)
fusion_features = torch.cat([features, roi_features], dim=1)
return self.fc(fusion_features)
images = torch.rand(4, 3, 224, 224)
model = CamFeatureFusion()
print(model(images).shape) # => torch.Size([4, 1])总结
- 该方案提出了一种非常简单的多图特征融合的方法,因为实现起来非常简单,也支持 batching,非常适合在 prototyping 或者 baseline 阶段尝试。
- CAM 主要用来提取「局部特征」,然后结合「全局特征」来做最后的预测,这种思路在很多场景下应该都是有效的;获取 RoI 不仅可以通过 CAM,也可以通过其他方式,比如 Object Detection 或是 Segmentation 等。